Salat im Training
Bei einem Regressionsproblem versucht der Entwickler, die Ausgabe eines kontinuierlichen Werts vorherzusagen, zum Beispiel der Temperatur oder des Gewichts. Im Gegensatz dazu zielt ein Klassifizierungsproblem darauf ab, eine bestimmte Klasse in einer Liste von Klassen zu identifizieren.
Um das Modell zu bauen, haben wir die mit Tensorflow 2.0 neu eingeführte tf.keras-API verwendet. Das Modell versucht, die Frischmasse (FM [6]) des Salats zu einem bestimmten Zeitpunkt nach der Pflanzung vorherzusagen. Dazu gilt es zunächst, das Forschungslabor aufzusetzen. Wir verwenden dazu Python 3.7, erzeugen eine virtuelle Umgebung und installieren dann Tensorflow (Listing 1, Zeile 1 bis 9). Über einen einfachen Befehl lässt sich anschließend prüfen, ob das Setup stimmig ist (Zeile 11).
Listing 1
$ python3 --version $ pip3 --version $ virtualenv --version $ virtualenv --system-site-packages -p python3 ./venv ### Umgebung aktivieren $ source ./venv/bin/activate ### Tensorflow-Distribution einrichten $ pip install --upgrade pip $ pip install --upgrade tensorflow=2.0 pandas numpy pathlib ### Tensorflow testen $ python -c "import tensorflow as tf;print(tf.reduce_sum(tf.random.normal([1000,**1000])))"
Neuronales Netzwerk bauen
Um den Entwurf des Modells einfach und leicht verständlich zu machen, betrachten wir im Folgenden die Gesichtspunkte aus der Tabelle “Zehn Merkmale”, wobei die Bewässerungssysteme in vier One-Hot-Spalten landen – es kommt stets nur eines der vier Systeme zum Einsatz.
|
Nummer |
Merkmal |
|---|---|
|
1 |
Blattfläche |
|
2 |
kumulierte Summe des Lichts |
|
3 |
kumulierte Summe des CO2 |
|
4 |
kumulierte Summe der Temperatur |
|
5 |
Tage nach der Pflanzung (DaP) |
|
6 |
Bewässerungssystem: Nutrient Film Technique (Hydroponik) |
|
7 |
Bewässerungssystem: Ebbe-Flut-System (Hydroponik) |
|
8 |
Bewässerungssystem: HPA (Aeroponik) |
|
9 |
Bewässerungssystem: Nebulisation (Aeroponik) |
|
10 |
Gewicht |
Da wir mit Daten von echten Sensoren arbeiten, die eventuell ausfallen und kalibriert werden müssen, spielt das Vermeiden fehlerhafter Ergebnisse eine entscheidend Rolle. Es ist daher wichtig, starke Preprocessing-Techniken wie Abtastung, Filterung und Normalisierung zu implementieren, bevor man die Daten in das neuronale Netzwerk speist. Einen Beispieldatensatz zeigt das Listing 2.
Listing 2
Weight DaP CumCO2 CumLight CumTemp LeafArea NFT HPA Ebb&Flood Nebu 135.0 10 4 1420.0 8623.0 156 0.0 1.0 0.0 0.0
Zunächst gilt es, den Datensatz in zwei Teile zu zerlegen, jeweils einen für das Training und einen für die Tests. Anschließend stellen die neun ersten Merkmale aus Tabelle 2 die Eingaben für das neuronale Netz dar. Das Gewicht, also den letzten Wert in der Tabelle, wollen wir vorhersagen. Es wird damit zur Ausgabe für das neuronale Netz.
Nun bauen wir das Modell auf (Listing 3). Dazu kommt ein einfaches sequenzielles Modell [7] mit zwei eng verbundenen verborgenen Schichten zum Einsatz. Dessen Ausgabeschicht liefert einen einzigen, kontinuierlichen Wert zurück: die Frischmasse des Salats.
Listing 3
import tensorflow as tf [...] model = tf.keras.Sequential([ tf.keras.layers.Dense(64, activation=tf.nn.relu, input_shape=[len(train_dataset.keys())]), tf.keras.layers.Dense(64, activation=tf.nn.relu), tf.keras.layers.Dense(1) ]) optimizer = tf.keras.optimizers.RMSprop(0.001) model.compile(loss='mean_squared_error', optimizer=optimizer, metrics=['mean_absolute_error', 'mean_squared_error'])
Wir wählen nur zwei verborgene Schichten, da es nicht viele Trainingsdaten und lediglich neun Merkmale gibt. In diesem Fall eignet sich ein kleines Netzwerk mit wenigen verborgenen Schichten besser, um eine Überanpassung zu vermeiden. Für die Aktivierungsfunktion fällt die Wahl auf den Gleichrichter (englisch ReLU, Rectified Linear Unit). Als Verlustfunktion kommt der Mean Square Error (MSE) zum Einsatz, der bei Regressionsproblemen hilft. Klassifikationsprobleme benötigen andere Verlustfunktionen.
Abbildung 4 zeigt noch einmal das Modell. Die Zahl der Inputs für das neuronale Netzwerk beträgt 9, was mit der Zahl an Input-Merkmalen korrespondiert. Im nächsten Schritt lässt sich das Modell mit dem Trainingsdatensatz trainieren (Listing 4).
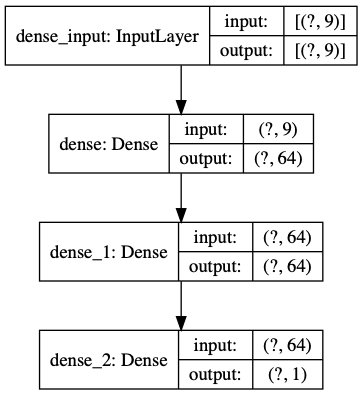
Abbildung 4: Als Input dienen dem eingesetzten Sequential-Modell die neun ersten Merkmale aus der Tabelle “Zehn Merkmale”. Das zehnte Merkmal ist der gesuchte Output.
Listing 4
model.fit(train_features, train_weights, epochs=100, validation_split=0.2, verbose=0))
Nach dem Training lässt sich das Modell speichern und exportieren (Listing 5). Wie sich zeigt, ist es insgesamt 86 077 Bytes groß und eignet sich damit noch nicht perfekt für Geräte mit begrenzten Ressourcen. Das lässt sich optimieren.




